
Dealing With Response Bodies - Latency Issues
The Simple Option: Buffered Requests
The main use-case for Bee Client is to make simple requests and get simple responses. Headers are easily set and retrieved. Likewise cookies are easily handled. All state is immutable in the basic case.
In this simple case, the response body (which may be empty) is buffered in a byte array and, when you need it, this is automatically converted to the equivalent string. For example:
... imports
object Example5a {
val httpClient = new HttpClient
def main(args: Array[String]) {
val response = httpClient.get("http://www.google.com/")
val body: ResponseBody = response.body
println(body.isBuffered) // true
println(body.isTextual) // true
println(body.contentLength) // a number
println(body.asBytes.length) // a similar number
println(body.asString.length) // a similar number
println(body.contentType.mediaType) // "text/html"
println(body.contentType.charsetOrUTF8) // "ISO8859-1" or similar
}
}
The two predicates isBuffered and isTextual indicate that this response body is buffered and contains textual content. The accessors asBytes and asString get the actual content, using the character encoding received in the content type to determine how the string will be converted. Remember to use isTextual if in doubt, because asString will throw an exception on binary data.
Such buffered requests are all very convenient. However…
Buffered Requests Increase Latency & Use More Memory
There are use cases that require lower latency I/O handling. Making a buffered request is very easy, but has two drawbacks:
- all the content has to be collected into the buffer before the
HttpClientreturns you theResponse; this can take (much) longer. - if the response body is large, it will have a (much) bigger memory footprint
In the first case, very large responses may have a latency that’s too high for your application. In the second case, very large responses might mean you might not have enough memory to handle many requests, or even any at all. If these are true for you, you may need to use unbuffered requests instead.
Unbuffered Requests Provide Streaming I/O
The primary purpose of an unbuffered request is to obtain a response that has not yet consumed the InputStream from the webserver.
* Line-by-Line Iteration
There’s an easy way to stream the input if it is textual: line by line using an iterator, as shown below:
... imports
object Example5b {
val httpClient = new HttpClient
def main(args: Array[String]) {
val request = Request.get("http://www.google.com/")
val response = httpClient.makeUnbufferedRequest(request)
val unbufferedBody = response.body
println(unbufferedBody.isBuffered) // false
println(unbufferedBody.isTextual) // true
// note that unbufferedBody.contentLength is not available
for (line <- unbufferedBody) {
println(line)
}
// not strictly necessary here
unbufferedBody.close()
}
}
The unbufferedBody here is an Iterable[String] that consumes the stream in steps. This is an easy way to reduce latency and minimise memory footprint for large responses. It also closes the input stream and the HTTP connection automatically, provided you consume the entire stream.
* Raw Stream
You can access the raw input stream should you need to. You must promise to close it though. Here’s an example:
import uk.co.bigbeeconsultants.http._
import uk.co.bigbeeconsultants.http.request.Request
import uk.co.bigbeeconsultants.http.response.InputStreamResponseBody
object Example5c {
val httpClient = new HttpClient
def main(args: Array[String]) {
val request = Request.get("http://www.bing.com/favicon.ico")
val response = httpClient.makeUnbufferedRequest(request)
if (response.body.isBuffered) {
// usually this means an unsuccessful request
// ...
} else {
val inputStream = response.body.inputStream
try {
println(response.body.isBuffered) // false
println(response.body.isTextual) // false
// ...use inputStream somewhow...
} finally {
inputStream.close() // very important
}
}
}
}
Be careful with the status code in the response. If it’s anything other than 200-OK, the response body will always be a buffered response. This sharply reduces the chance of memory leaks caused by forgetting to close the input stream in error cases. So the example above tests whether the response.body.isBuffered, thereby avoiding a ClassCastException that would occur if the status had been anything other than 200-OK.
Converting the response body type
There is a one-way conversion from an unbuffered response body to a buffered one. There is also a further conversion from the buffered body based on a byte array to an equivalent one based on a string.
The conversion sequence between the different kinds is
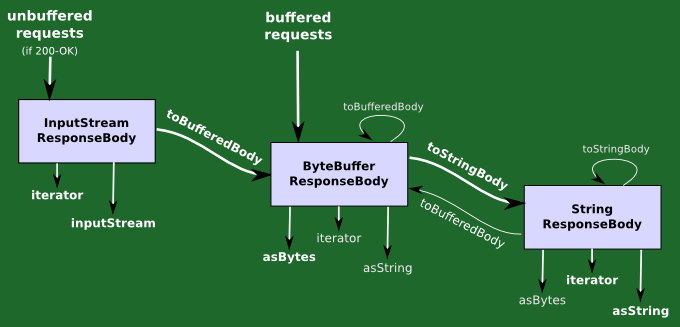
InputStreamResponseBody provides unbuffered access to the content via an InputStream.
ByteBufferResponseBody holds a buffer containing either binary or textual data. If the data is binary and you attempt to convert it to a string via asString, the string you get will be empty.
StringResponseBody holds a buffer containing text. This is also useful for test code.
EmptyResponseBody is not shown on the diagram above but it is simple: it is always empty. These are used when the webserver returns no content.
The four types of ResponseBody are all Iterable[String], but only the buffered ones can be traversed more than once.
They are converted simply by calling the toBufferedBody or toStringBody on any of them. All types provide iterator, asBytes and asString access methods; in the diagram, the ‘easy’ accessors are in bold, whereas the ones in feint require some preliminary conversion (done for you automatically). All types also provide an inputStream accessor to get the content as a java.io.InputStream; this is a vital part of the unbuffered InputStreamResponseBody
Remember that binary data cannot be converted to a string; asString and iterator will throw an exception if the content is binary.
This example illustrates the three main kinds in use:
... imports
object Example5d {
val httpClient = new HttpClient
def main(args: Array[String]) {
val request = Request.get("http://www.google.com/")
val response = httpClient.makeUnbufferedRequest(request)
val unbufferedBody: ResponseBody = response.body
// unbufferedBody is an InputStreamResponseBody
// (only if response.status.code == 200)
println(unbufferedBody.isBuffered) // false (if no error)
val bufferedBody: ResponseBody = unbufferedBody.toBufferedBody
// bufferedBody is a ByteBufferResponseBody
println(bufferedBody.isBuffered) // true
println(bufferedBody.contentLength) // now known
val stringBody: ResponseBody = bufferedBody.toBufferedBody
// stringBody is a StringResponseBody
println(stringBody.isBuffered) // true
}
}
If you start consuming from an unbuffered input stream and then convert it to a buffered one, you will get what’s still to be read from the webserver, but lose the part you’ve already consumed. This is ok; had you really wanted to make multiple passes through the data, you would have buffered the data from the very beginning instead.
Dealing With Request Bodies
We’ve discussed the handling of response bodies at great length above. It’s also possible to cut the latency and memory footprint for request bodies.
Streaming Data Into The Request Body
A RequestBody can allow I/O streaming. Simply choose between the following concrete implementations when composing a RequestBody for PUT or POST requests:
- a
StreamRequestBodyallows use of an unbuffered source; you provide a closure function that writes to anOutputStream - a
BinaryRequestBodyholds a (buffered) byte array - a
StringRequestBodyholds a (buffered) string - this is the most common case